Found an interesting paper and don’t have time to read it right now? Today we are adding a reading list to your Scholar Library to help you save papers and read them later.
You can also use it to save papers you find off-campus but want to read on-campus where you have access to the full text, or papers you find on your smartphone but want to read on a larger screen.
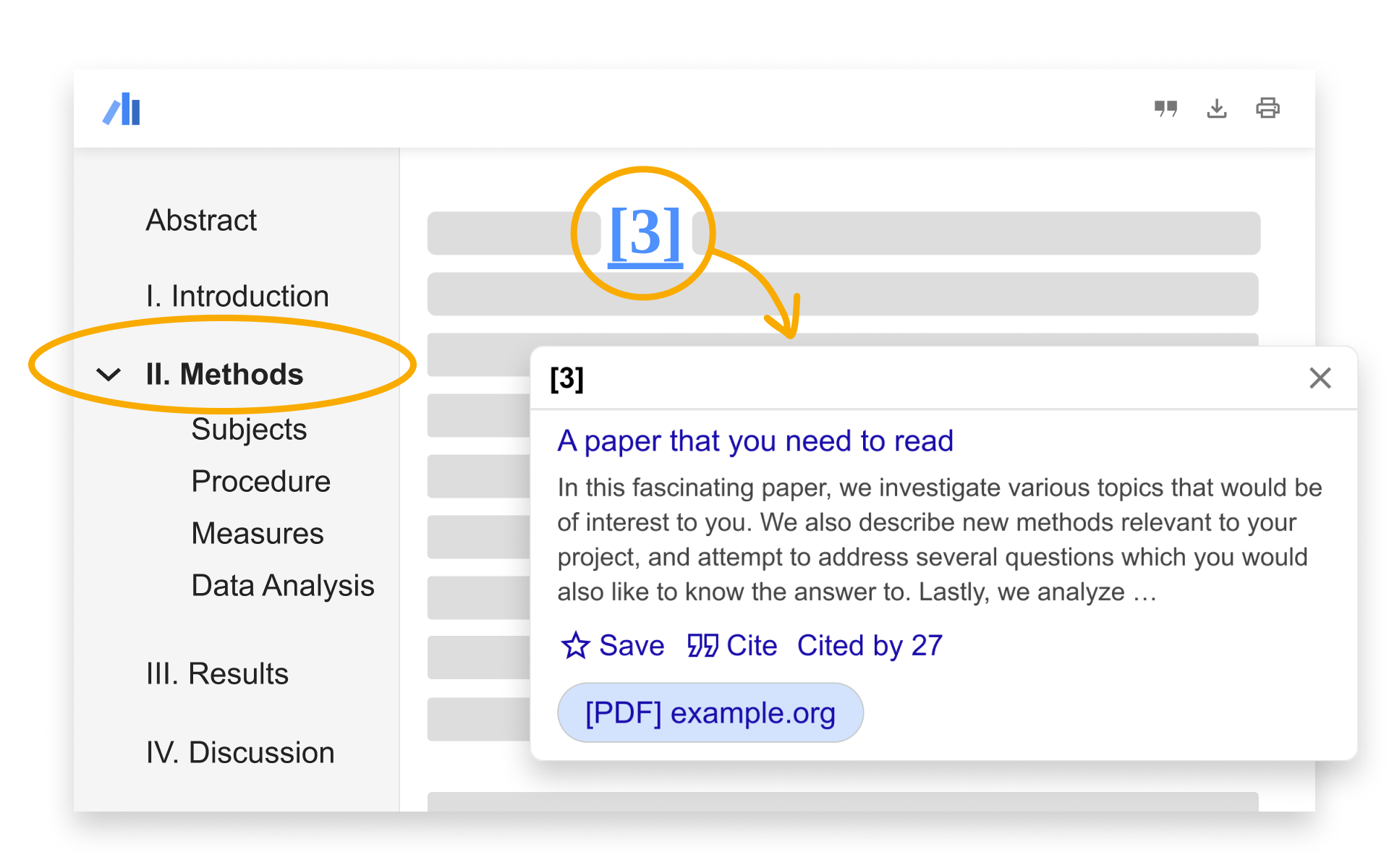
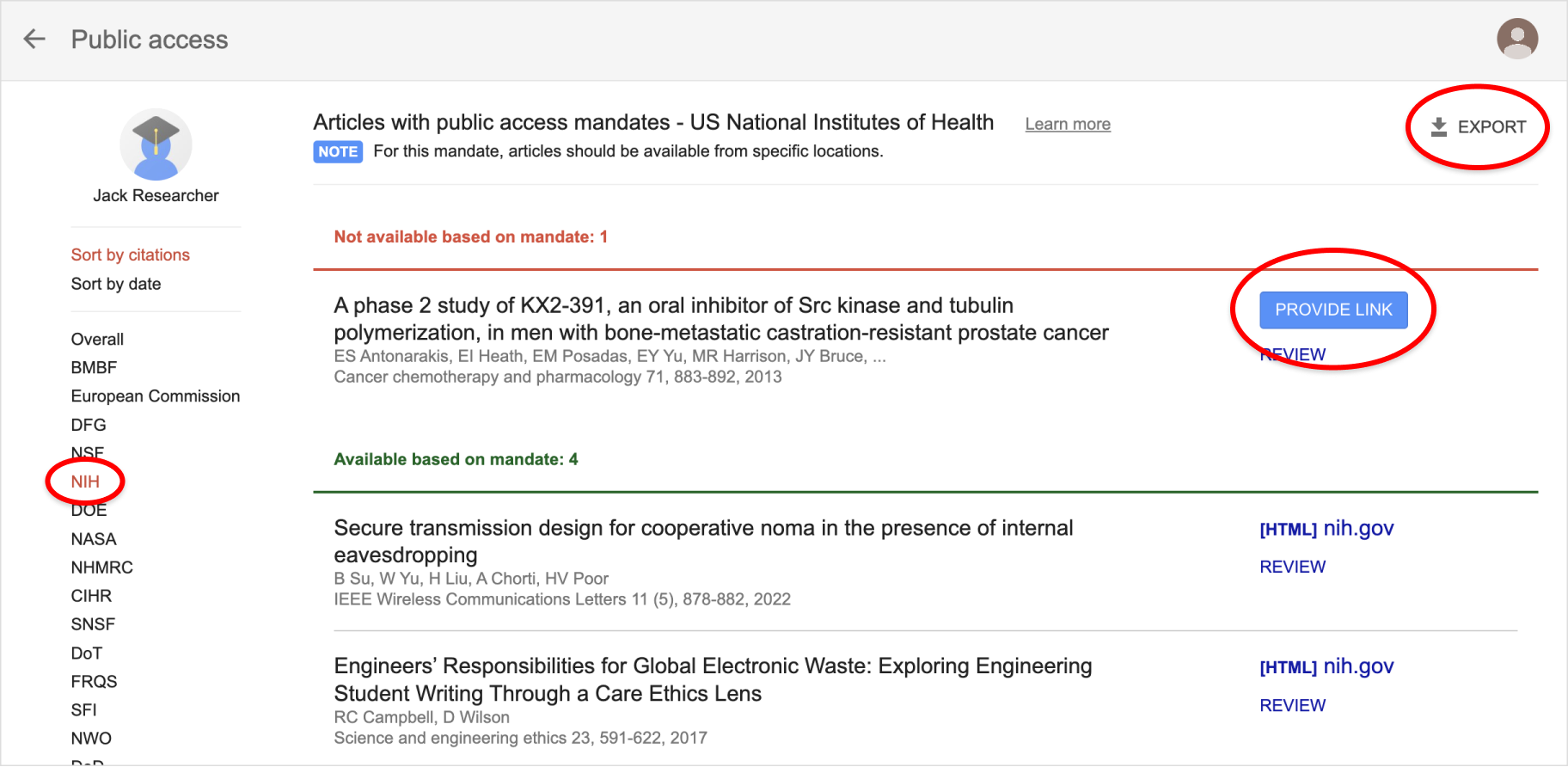
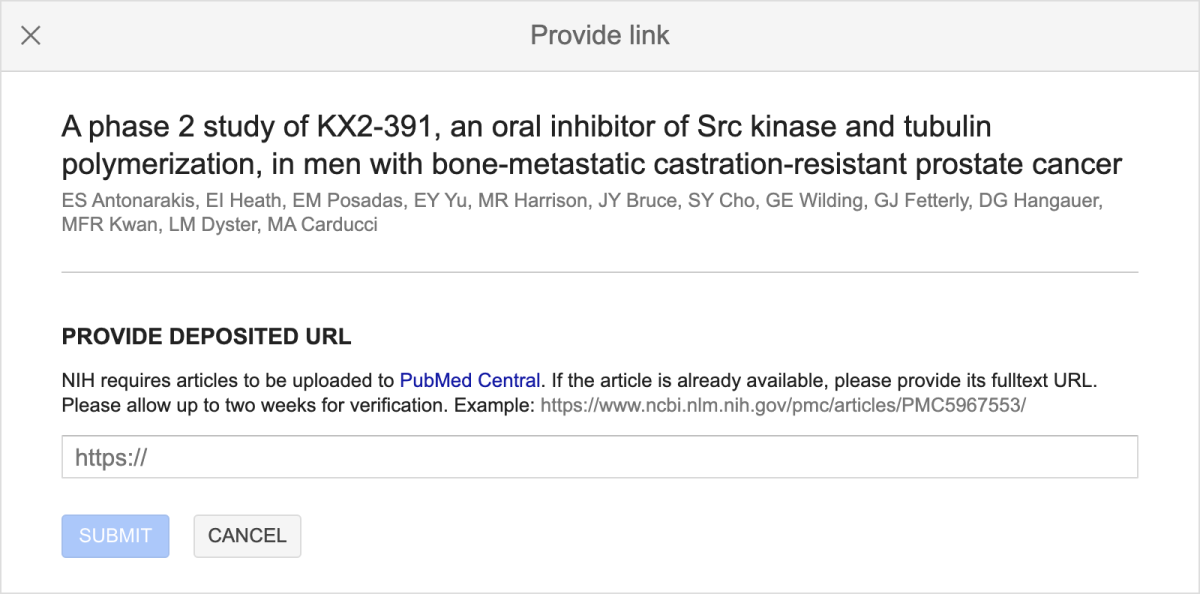
To add a paper to your reading list, click “Save” and add the “Reading list” label. To use this feature, you need to be signed in to your Google account.
To get to your reading list, click “My library”:
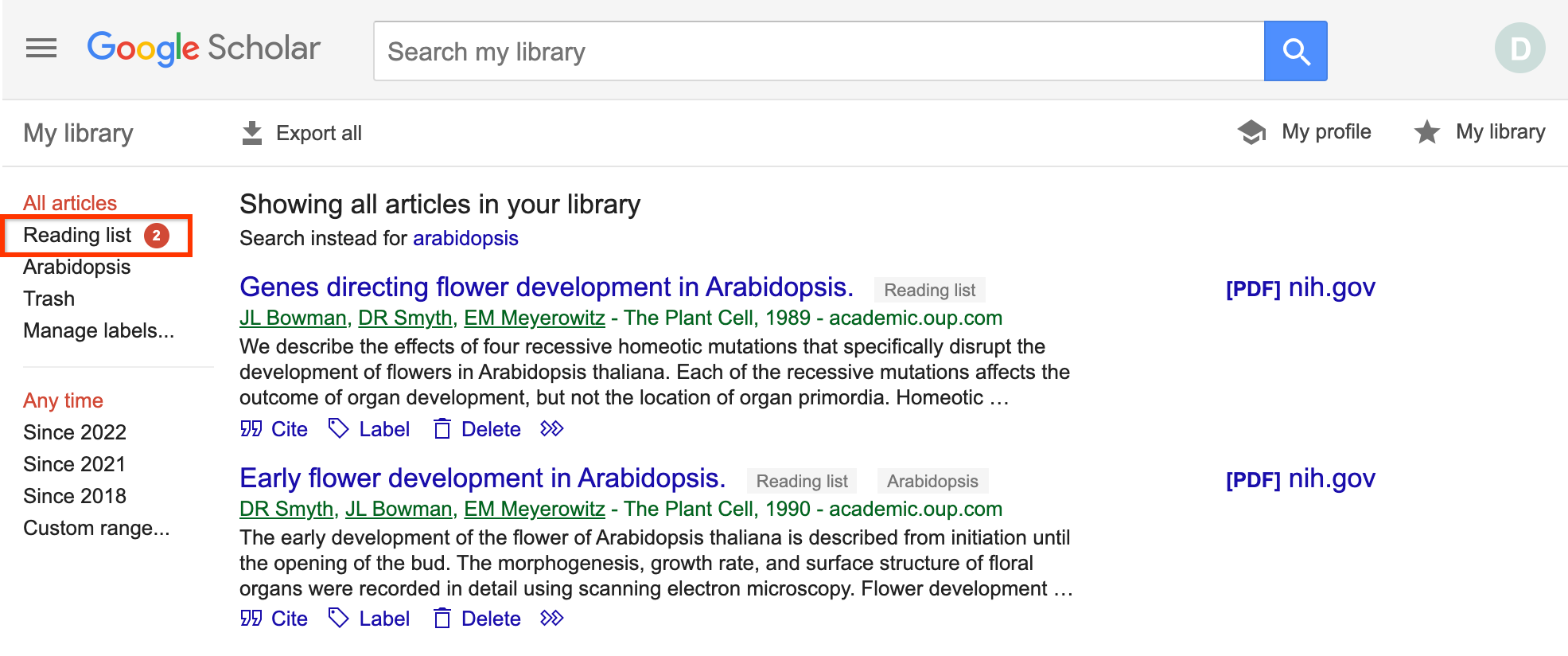
…and select “Reading list” in the sidebar.
To read the paper, click the [PDF] or [HTML] link next to its title.
After reading a paper, click "Archive" or "Delete" to remove it from your reading list. Archived papers are kept in your library for later reference; deleted papers are removed from your library.
Now you can gather papers as you go, block off a good chunk of time, and dig into the details.
Posted by: Danni Chen, Kyu Jin Hwang, and Alex Verstak